
NLP Эмбеддинги
Эмбеддинги - это модель, которая позволяет предсказать близкие по смыслу слова, или слова которые чаще всего употребляются друг с другом.
Построить эту модель можно следующим образом:
- Текст нужно разделить на словосочетания из нечетного количества слов. Например 3 или 5 слов. Это называют Context Window.
- На вход модели подается центральное слово из Context Window в формате one-hot вектора.
- На выход модели подаются слова которые идут следом или перед ним. Для Context Windows = 3, это будут 2 one hot вектора (предыдущее слово и следующее слово), либо сумма этих 2х векторов (bag of words). Если Context Window будет равным 5, то слов будет 4, а не 2.
- Затем нужно сдвинуть Context Window на один шаг и повторить процедуру.
Таким образом мы создадим датасет для обучения. Этот датасет мы подадим в автоенкодер для обучения.
Такая модель называется Skip Gram (Когда на входе центральное слово, а на выходе то что его окружает). CBOW - это наоборот, когда мы в модель подаем то что окружает слово, а на выходе получаем центральное слово.
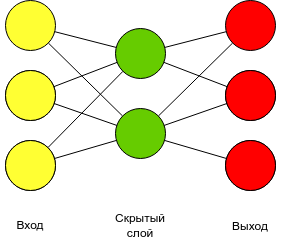
Размер входного слоя и выходного слоя равен размеру словаря. Входной слой и скрытый слой кодируют слово. Скрытый слой и выход декодируют слово. Таким образом можно, закодировать one hot вектора в эмбеддинг. А вектор эмбединга будет заметно меньше, чем one-hot вектор. Эмбедингом называется матрица весов между входом и скрытым слоем. Или значения, которые возникают на скрытом слое, при подаче one-hot вектора слова в модель.
Эмбеддинг, в дальнейшем можно передать в классификатор, вместо Bag of words. Делается это следующим образом:
- Береться строка и каждому слову ставятся индексы из словоря. Получается вектор индексов.
- Затем для каждого слова, нужно поставить его эмбединг по индексу слова. Получается двумерный вектор размером [ длина строки ] X [ размер эмбединга ]. Например, 300 x 50.
- После этого, этот вектор надо передать в классификатор. Т.к. используются уже двумерные слои, можно использовать сверточные сети.
Это будет уже новая нейронная сеть, которая принимает на вход индексы слов, превращает их в вектор эмбединга, а после отправить результат в классификатор. И данную сеть можно обучать, в том числе обучить и эмбединг. Можно взять готовый эмбединг, а можно обучить его самостоятельно.
model = ai.CustomModel(
model_name = "Model_embedding_1",
input_shape = input_shape,
module = nn.Sequential(
nn.Embedding(10000, 50),
Transform_Flat(),
nn.Linear(300*50, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 256),
nn.ReLU(inplace=True),
nn.Linear(256, output_shape[0]),
nn.Softmax(dim=-1),
),
)